维护一组提供较强一致性的小型集群(共识核心 Consistent Core),以允许大型数据集群协调服务器活动,而无需自行实现基于quorum的算法。
原文
问题
当一个集群需要处理大量数据时,它需要更多的服务器。对于集群服务器,有一些共同的要求:例如选择特定的服务器作为特定任务的主服务器(master);管理集群成员信息;管理数据分片到服务器的映射等。这些要求都需要强一致性的保证,即线性度(linearizability)。并且这种实现也必须具有容错性。一种常见的方法是使用基于Quorum的容错共识算法,但基于 Quorum 的系统,其吞吐量会随着集群的增大而降低。
方案
实现一个较小的,3 到 5 个节点的集群来提供线性度保证和容错能力。单独的数据集群可使用小型共识集群来管理元数据,并使用诸如Lease之类的原语来做出集群范围的决策。这样数据集群可以扩容至拥有大量服务器,但是仍能使用较小的元数据集群执行某些需要强一致性保证的操作。
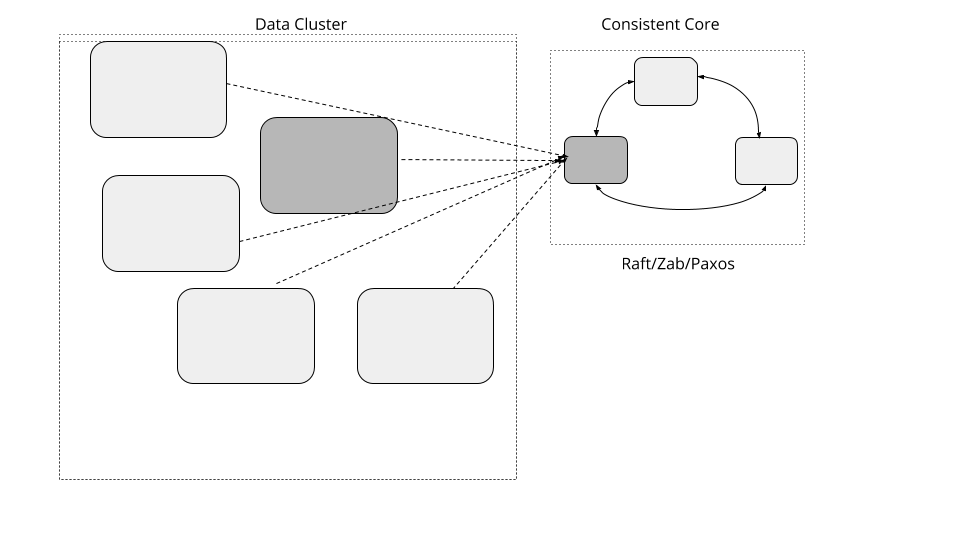
共识核心的典型接口如下:
1
2
3
4
5
6
7
8
9
10
11
|
public interface ConsistentCore {
CompletableFuture put(String key, String value);
List<String> get(String keyPrefix);
CompletableFuture registerLease(String name, long ttl);
void refreshLease(String name);
void watch(String name, Consumer<WatchEvent> watchCallback);
}
|
共识核心至少需要提供一种简单的键值存储机制,它用于存储元数据。
元数据存储
存储机制时由 Raft 之类的共识算法来实现的。Raft 算法是“复制预写日志”(Replicated Write Ahead Log)的实现,在其中Leader and Followers机制用于实现复制,High-Water Mark机制用于标记基于 Quorum 的成功复制的副本。
支持分层存储
共识核心通常用来存储像这样的数据:集群成员或跨服务器的任务调度。一种常见的方式是使用前缀来限定元数据的类型。例如,对于集群成员,键将全部存储为/servers/1,/servers/2等。对于分配给服务器的任务,键可以是/tasks/task1,/tasks/task2。通常使用所有键带有的特定前缀来读取此数据。比如要获取集群所有服务器的信息,将读取所有前缀带/servers的键。
下面是一个使用用例:
服务器可以通过创建带有/servers的键向共识核心注册自己。
1
2
3
4
5
|
client1.setValue("/servers/1", "{address:192.168.199.10, port:8000}");
client2.setValue("/servers/2", "{address:192.168.199.11, port:8000}");
client3.setValue("/servers/3", "{address:192.168.199.12, port:8000}");
|
客户端可以通过读取带有/servers/前缀的键来获取所有该集群中的服务器:
1
2
3
4
|
assertEquals(client1.getValue("/servers"),
Arrays.asList("{address:192.168.199.12, port:8000}",
" {address:192.168.199.11, port:8000}",
"{address:192.168.199.10, port:8000}"));
|
由于数据存储的这种分层性质,zookeeper, chubby 这样的软件提供了类似文件系统的接口,用户可以调用创建目录、文件或者节点,并拥有父节点和子节点的概念。etcd3因拥有平坦键空间而可以读取一个区间内的键。
处理客户端交互
共识核心功能的关键要求之一是客户端如何和核心交互。以下几个方面对于客户端和共识核心的交互来说是至关重要的。
寻找 Leader
所有的操作都必须在 Leader 上执行是相当重要的,所以客户端需要先找到 Leader 服务器。下面有两种可行并满足要求的方案:
- 共识核心中的 Follower 服务器知道当前的 Leader 信息,因此如果客户端连接到 Follower 服务器,服务器就能返回 Leader 的地址。然后客户端就能直接连接至在响应中识别出的 Leader 服务器地址。 应该注意的是,当客户端试图连接时,服务器可能正在进行 Leader 选举。这种情况下,服务器不能返回 Leader 的地址,而客户端需要等待并尝试连接其他服务器。
- 服务器可以实现转发机制,并转发所有客户端的请求到 Leader。这使得客户端可以连接到任何服务器。同样的,如果服务器正在进行 Leader 选举,那么客户端需要重试,直到 Leader 选举成功并选出一个合法的 Leader 为止。
像 zookeeper 和 etcd 这样的软件都使用第二种方式实现,因为它们允许一些只读的请求由 Follower 服务器处理。这避免了大量客户端都发起只读请求的情况下,Leader 服务器出现性能瓶颈。这也减轻了客户端根据请求类型连接到 Leader 或 Follower 的复杂度。
寻找 Leader 的一种简单机制是:尝试连接到每个服务器并尝试发送请求,如果服务器不是 Leader,它会返回重定向响应。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
private void establishConnectionToLeader(List<InetAddressAndPort> servers) {
for (InetAddressAndPort server : servers) {
try {
SingleSocketChannel socketChannel = new SingleSocketChannel(server, 10);
logger.info("Trying to connect to " + server);
RequestOrResponse response = sendConnectRequest(socketChannel);
if (isRedirectResponse(response)) {
redirectToLeader(response);
break;
} else if (isLookingForLeader(response)) {
logger.info("Server is looking for leader. Trying next server");
continue;
} else { //we know the leader
logger.info("Found leader. Establishing a new connection.");
newPipelinedConnection(server);
break;
}
} catch (IOException e) {
logger.info("Unable to connect to " + server);
//try next server
}
}
}
private boolean isLookingForLeader(RequestOrResponse requestOrResponse) {
return requestOrResponse.getRequestId() == RequestId.LookingForLeader.getId();
}
private void redirectToLeader(RequestOrResponse response) {
RedirectToLeaderResponse redirectResponse = deserialize(response);
newPipelinedConnection(redirectResponse.leaderAddress);
logger.info("Connected to the new leader "
+ redirectResponse.leaderServerId
+ " " + redirectResponse.leaderAddress
+ ". Checking connection");
}
private boolean isRedirectResponse(RequestOrResponse requestOrResponse) {
return requestOrResponse.getRequestId() == RequestId.RedirectToLeader.getId();
}
|
仅仅建立 TCP 连接是不够的,我们需要知道服务器能否处理我们的请求。所以客户端发送一个特殊的连接请求,让服务器确认它能否处理请求,否则就重定向到 Leader 服务器。
1
2
3
4
5
6
7
8
9
10
|
private RequestOrResponse sendConnectRequest(SingleSocketChannel socketChannel) throws IOException {
RequestOrResponse request
= new RequestOrResponse(RequestId.ConnectRequest.getId(), "CONNECT", 0);
try {
return socketChannel.blockingSend(request);
} catch (IOException e) {
resetConnectionToLeader();
throw e;
}
}
|
如果现有的 Leader 服务器宕机了,相同的技术被用来确定从集群中新选出的 Leader。
一旦连接,客户端就会维持一个单套接字通道(Single Socket Channel)到 Leader 服务器。
处理重复请求
在请求失败的情况下,客户端可能尝试连接至新的 leader,并重新发送请求。但是如果这些请求在失败之前已经被宕机的 leader 处理了,就可能导致重复处理。因此,在服务器上设置一个忽略重复请求的制止时很重要的。Idempotent Receiver 模式就被用来实现重复检测。
协调一组服务器之间的任务可以通过使用Lease来完成。它同样可以用来实现组成员和故障检测机制。
State Watch 用来获取元数据或限时租约的变化通知。
例子
众所周知,谷歌使用[chubby]锁服务进行协调和元数据管理。
[kafka] 使用 [zookeeper]来管理元数据并做出决定,如集群选主。 Kafka 的架构提议变化将用它自己基于 Raft 的控制集群来取代 zookeeper。
[bookkeeper]使用 zookeeper 来管理集群元数据。
[kubernetes] 使用 [etcd] 来协调管理机群元数据和成员信息。
所有的大数据存储和处理系统,如 [hdfs], [spark]和 [flink] 都使用 [zookeeper]来实现高可用和集群协调。