MapReduce 6.824
Contents
MapReduce Framework: Users define map function that processes a key/value pair to generate a set of intermediate k/v pairs; A reduce function that merge all intermediate k/v pairs associated with the same intermediate key.
MapReduce Framework hides the messy details of parallelization, fault-tolerance, data distribution and load balancing in a library.
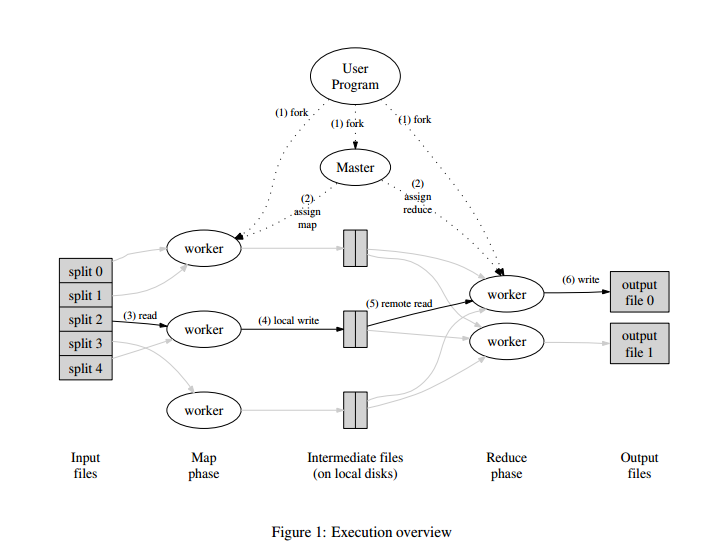
Execution Overview
-
Split input data into a set of M splits
-
Master assigned task to work
-
Worker call map function and produces intermediate files
-
Partitioning the intermediate key into R pieces using partitioning function(like
hash*(key) mode R). Map阶段将key分成R份,由R个reduce task来处理,一共有M个map task。map阶段完成后,一共有M*R个文件。 -
Reduce worker collects the same intermediate keys(one of the R pieces partition)
-
Worker call reduce, produces the final outputs.
Master Data Structure
- For each map task and reduce task, it stores the state (idle, in-progress,or completed)
- for each completed map task, the master stores the locations and sizes of the R intermediate file regions .
Fault Tolerance
Worker Failure
The master ping every worker periodically.
-
If no response is received from a worker in a certain amount of time, the master marks the worker as failed.
-
The task is reset to idle state and rescheduling to other workers.
Master Failure
Aborts the MapReduce computation if the master fails.
问题
看过论文有个疑惑,Map阶段和Reduce阶段可以并行吗?应该是不行?因为没有运行完Map阶段的所有任务,所产生的intermediate file数据是不完整,这时候去运行Reduce也没用。Lab1里也印证了这一点,只有全部Map task完成后,才开始Reduce task。
Workers will sometimes need to wait, e.g. reduces can’t start until the last map has finished.
Lab1
和论文中的描述不同,Lab1由worker向master发起RPC请求任务(单向RPC),而不是worker向master注册,master再主动分配任务(双向RPC)。master有两个RPC调用:``AssignTask,DoneTask`
-
Master存储任务和其状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16type WorkerTask struct { filename string // for map tasks state TaskState id int // for non-idle tasks } type Master struct { allMapTaksDone bool allReduceTaksDone bool mapTask []WorkerTask reduceTask []WorkerTask nReduce int nFiles int sync.Mutex } -
worker函数死循环获取任务
1 2 3 4 5 6 7 8 9 10 11 12 13func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) { for { time.Sleep(time.Second) reply := askTask() if reply.Phase == MapPhase { go doMapTask(mapf, reply.File, reply.Id, reply.NumForOtherPhase) } else if reply.Phase == ReducePhase { go doReduceTask(reducef, reply.Id, reply.NumForOtherPhase) } } } -
AssignTask:给worker分配任务,1 2 3 4 5 6 7 8 9type TaskReply struct { File string // only for map phase Phase JobPhase Id int //task index // for map, it's nReduce to naming the intermediate file, // for reduce, it's nFile to collect intermediate files NumForOtherPhase int Kill bool // all task done, kill the worker } -
DoneTask:任务完成,包含完成任务的id和阶段1 2 3 4 5type TaskDoneArgs struct { Id int // done task id Phase JobPhase // TempFiles *[]os.File }
Fault Tolerance
在Lab1的提示中已经给出容错处理的方法:Master分配任务后,开新线程等待10秒,如果该任务还没完成就判断为失败,重新分配任务。
不过依旧有一个reduce parallelism test没过,不知道哪有问题了。一边看论文,一边写,Lab1用了16个小时,我好菜啊,下一课。。。