C语言-可怕的指针
Contents
一重指针
简单使用
|
|
数组指针
-
数组名代表数组的首地址,二维数组名则是行地址。
-
一维数组
1 2 3 4int a[4] = {1, 2, 3, 4}; int *p1 = a; printf("%d", a[1]); //2 printf("%d", (*++p1)); //2 -
二维(多维)数组
1 2 3 4 5 6 7int b[2][4] = {{1, 2, 3 ,4},{5., 6, 7, 8}}; int (*p2)[4] = b; //**A pointer** to a array of 4 integers,行地址 int (*p3)[2][4] = &b; //**A pointer** to 2d array b[1][1];//5 *((*p2 + 1) + 1); //5,(*p + 1) == 一维数组b[1]的首地址 p2[1][1]; //5 (*p2)[1][1]; //5
字符串和字符数组
对于 “assignment to expression with array type” 这样的错误就是没有分清字符串和字符数组的区别
|
|
-
赋值方式不同,数组和指针都可以进行初始化,但是数组不能再次进行整体赋值。
-
存储内容肯定不一样,数组存储字符串本身,字符型指针存储字符串的首地址
-
指针变量可以改变值(值为地址),数组则不行。
1 2s1 += 1; //s1 = "ello" s2 += 1; //error, assignment to expression with array type
指针数组
-
字符串指针数组
1 2 3char *strings[] = {"Hello", "world!"}; //a array of **two pointers**, which point to a string strings[0]; //Hello strings[1]; //world!
二重(多重)指针
|
|
二重指针存储的是一个指针的地址。就是指针的指针(。
上面的例子可以表示如下图:
|
|
二重指针可以对一重的指针数组进行操作,如 cur_string + 1就和 cur_string[1]的值是一样的。
一个编程中遇到的问题
在写一元多项式的按次数排序时,使用 stdlib.h 中的快速排序算法 qsort 时, 排序之后的结果总是和排序之前一模一样。
结构体是长这样的:
|
|
生成多项式的函数是这样的:
|
|
那么只能用佛系调试法,在第四行的地方查看输出的次数(power)。结果很明显,输出并不是次数啊,而是一长串数字。虽然也猜到是指针了, 如果 item1 是 Item 的指针的话, 那么 p1->power 又是什么,是 p1->power 的指针?
这时只能面向 Stackoverflow 编程,于是乎,还真有人遇到了和我一样的问题:
Sorting an array of struct pointers using qsort
Your code suggests that you are actually trying sort an array of pointers to struct.
In this case you are missing a level of indirection. You also have your directions reversed.
虽然验证了自己的猜测是对的,但是我没看到这个答案前并不知道怎么做,是菜鸡。
于是,把比较函数改成这样就行了:
|
|
Linus 关于指针的例子
For example, I’ve seen too many people who delete a singly-linked list entry by keeping track of the “prev” entry, and then to delete the entry, doing something like
if (prev) prev->next = entry->next; else list_head = entry->next;
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head. And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”.
这里 Linus 在 slashdot 上举的一个关于单链表的例子。
对于一个单链表,在删除节点的时候,需要先得到 prev 节点,利用它判断是否 current 是否为头节点。Linus 大神说不懂指针的人才会这样做。真的也只有大神才敢这样说,不过下面的评论里也有很多人反对 Linus 这种做法。
Linus 说的 by just doing a "*pp = entry->next". 到底是什么意思呢?完整的代码可以看这里。
|
|
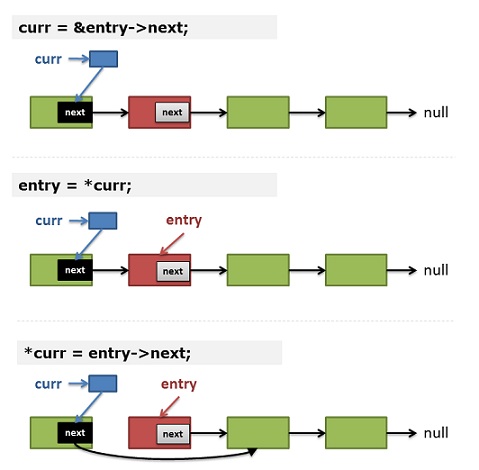
这样做代码更加简单,但是如果不了解指针的话,貌似也更难懂了呢。两个星星就是二重指针,我第一次看到二重指针还可以这样,很惊艳。
curr是一个指向指针的指针, 也就是entry->next这个指针的指针。- 在下一次循环的时候,
entry为*curr,对二重指针取值,也那么就是prev->next。 - 这时如果要删除
entry,就把curr所指的值(也是一个指针)改为entry->next。于是prev->next就成了entry->next。 - 最后
freeentry。
看图更加清楚:
我也在书上看到一种删除节点方法。单链表有一个 dummy header,也就是第一个节点为 header, 从第二个节点开始才是存储用户数据的。这样的话也不需要判断是否为头节点。但还是需要一个prev 节点。
可能你看到这里还是不理解二重指针到底是什么?有什么用处?
我现在的理解是,比如说在我们希望给函数传一个值,并且在这个函数里改变它的值。如果直接传值的话(BTW,C 语言里函数之间的值传递,只是拷贝一份而不是操作原来的变量)为了解决这个问题,那么指针(一重)就出现了。可以向函数传递一个普通变量的指针(在内存中的地址),我们知道了地址就可以直接对原变量进行操作。curr = entry->next,仅仅是把 entry->next 的值复制给 curr;
而二重指针,其中一重指针就相当于原来的普通变量,我们得到这个指针在内存中的地址,也就可以对这个指针的值进行改动。*curr = &entry->next 不是这个值的 copy,它是这个变量的地址,它也得到了 entry->next 这个变量的读写权。
不能再说了,我自己都要糊涂了。
函数指针
函数指针照说也是一重指针,但是有比较特殊。函数指针指向的是函数在内存中的入口地址,这样就可以利用函数指针来调用函数,把“函数”作为函数的参数。
一个简单的例子:
|
|
- 函数指针的定义类似于:
int (*POINTER_NAME)(int a, int b), POINTER_NAME 为 指针的名字,指向函数。 - 用
typedef来简化 函数指针的申明:typedef int (*POINTER_NAME)(int a, int b)。